
The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset.
However, the pretraining datasets for state-of-the-art open LLMs like Llama 3
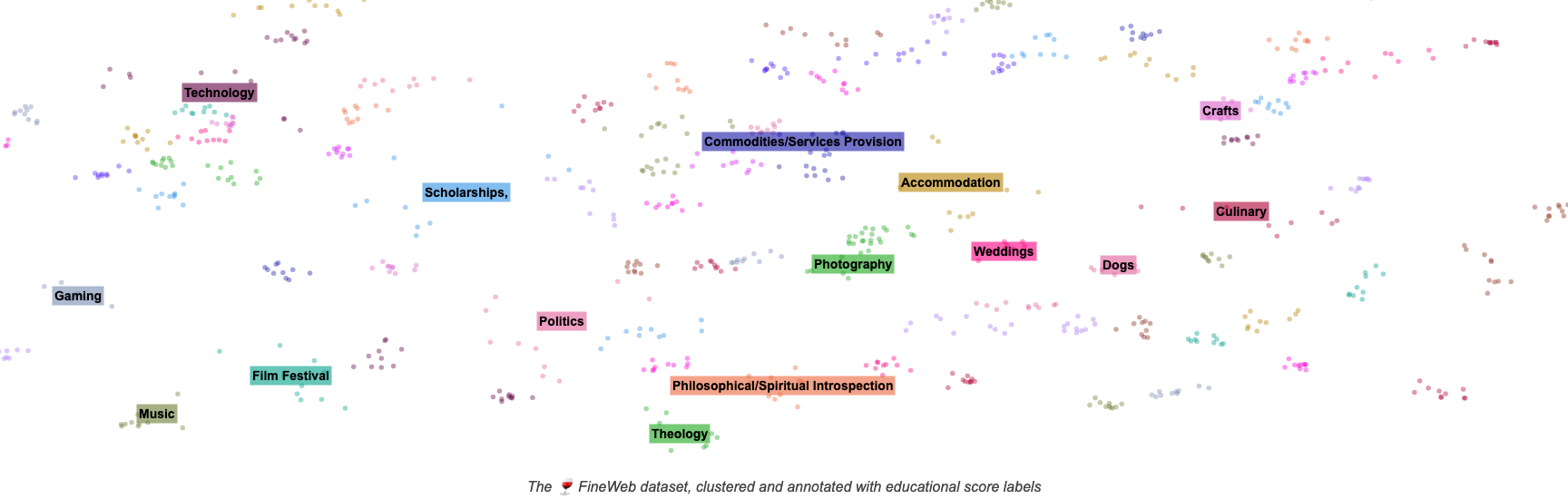
Recently, we released 🍷 FineWeb, a new, large-scale (15-trillion tokens, 44TB disk space) dataset for LLM pretraining. FineWeb is derived from 96 CommonCrawl snapshots and produces better-performing LLMs than other open pretraining datasets. To bring more clarity in machine learning and advance the open understanding of how to train good quality large language models, we carefully documented and ablated all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. The present long form report is a deep dive in how to create a large and high-quality web-scale dataset for LLM pretraining. The dataset itself, 🍷 FineWeb, is available here.
In this report we also introduce 📚 FineWeb-Edu, a subset of FineWeb constructed using scalable automated high-quality annotations for educational value, and which outperforms all openly accessible web-datasets on a number of educational benchmarks such as MMLU, ARC, and OpenBookQA.
📚 FineWeb-Edu is available in two sizes/filtering-level: 1.3 trillion (very high educational content) and 5.4 trillion (high educational content) tokens (all tokens are measured with GPT2 tokenizer
Both datasets are released under the permissive ODC-By 1.0 license
TLDR: This blog covers a discussion on processing and evaluating data quality at scale, the 🍷 FineWeb recipe (listing and explaining all of our design choices), and the process followed to create its 📚 FineWeb-Edu subset.
A common question often asked regarding web datasets used to train LLMs is “where do they even get all that data?”. There are generally two options:
To build 🍷 FineWeb, following what has been done in the past by a number of LLM training teams, we used CommonCrawl (CC) as a starting point. The Common Crawl non–profit organization has been crawling the web since 2007 and releases a new crawl containing 200 to 400 TiB of textual content obtained via automatic web crawling usually every 1 or 2 months.
As an example, the latest CC crawl (April 2024) contains 2.7
billion web pages, totaling 386 TiB of uncompressed HTML text content
Given the sheer size of the data involved, one of the main challenges we had to overcome was having a modular, scalable codebase that would allow us to quickly iterate on our processing decisions and easily try out new ideas, while appropriately parallelizing our workloads and providing clear insights into the data.
For this purpose, we developed datatrovedatatrove repository.
This is probably the main question to keep in mind when
creating a dataset. In most contexts and, in particular, in the context of large language model pretraining
It is still common to train a model on a given corpus considered "clean"
(typically wikipedia
Yet another way to compare different datasets would be to
train a model on each dataset and have humans rate and compare the generations of the models (like on the LMSYS Chatbot Arena)
In this work, we went with the approach of training small models and evaluating them on a set of "early-signal" benchmark tasks. We believe this is a reasonable proxy for the quality of the data used to train these models, when keeping in mind the above-mentioned caveat around overfitting on the evaluation benchmarks.
To compare the impact of a given processing step, we trained two models on two versions of the dataset, one version processed with the extra step (the one we wish to evaluate) and another version with this step ablated (cut/removed). Apart from the data, these two models would be otherwise identical: the same number of parameters, architecture hyper-parameters, and trained on an equal number of randomly sampled tokens from each version of the data, for a single epoch — the only difference being thus the training data. We then evaluated each model on the same set of tasks and compared average scores.
Our ablation models were trained using nanotron. Our "ablation models" have 1.82B parameters (including embeddings), used the Llama
architecture with a 2048 sequence length, a global batch size of ~2 million tokens, and the GPT2 tokenizer. For most
ablations we trained on ~28B tokens (roughly the Chinchilla
We evaluated the models using lighteval. We carefully selected a set of benchmark for ablations by selecting
benchmarks that would provide good signal at a relatively small scale ("small" models trained on only "a few
billion" tokens). We generally used the following criteria to select these benchmarks among all the benchmarks available in lighteval:
After consideration, we selected the following list of benchmarks:
To ensure our checkpoint evaluation stayed within a limited timeframe, we capped the longer benchmarks at 1000 samples (wall-clock evaluation taking less than 5 min on a single node of 8 GPUs - done in parallel to the training).
In the next subsections we will explain each of the steps taken to produce the FineWeb dataset.
CommonCrawl data is available in two main formats: WARC and WET. WARC (Web ARChive format) files contain the raw data from the crawl, including the full page HTML and request metadata. WET (WARC Encapsulated Text) files provide a text only version of those websites.
A large number of datasets take the WET files as their
starting point. In our experience the default text extraction used by Common Crawl to create these WET files is suboptimal for the goals of LLM pretraining
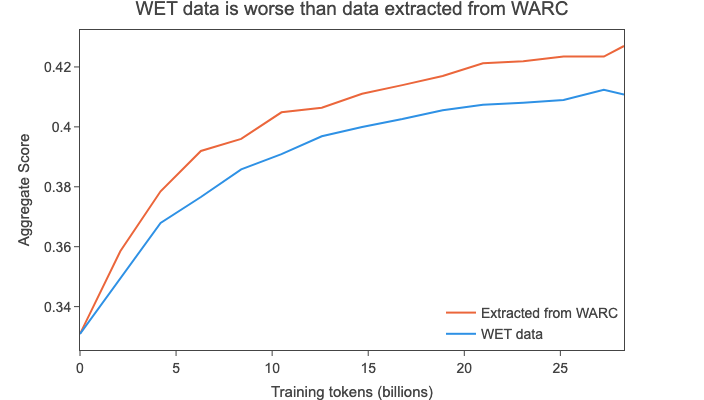
To validate this decision, we processed the 2019-18 dump
directly using the WET files and with text extracted from WARC files using trafilaturafavour_precision=True.
It is important to note, however, that text extraction is one of the most costly steps of our processing, so we believe that using the readily available WET data could be a reasonable trade-off for lower budget teams.
Filtering is an important part of the curation process. It consists in removing part of the data (be it words, lines, or even full documents) that lowers the performance of the model and is thus deemed to be “lower quality” in our eval-driven process of dataset crafting.
As a basis for our filtering we used part of the setup
from RefinedWeb
After applying this filtering to each of the text
extracted dumps (there are currently 96 dumps) we obtained roughly 36 trillion tokens of datagpt2 tokenizer
Deduplication is one of the most important steps when creating large web datasets for LLM pretraining. Methods to deduplicate datasets attempt to identify and remove redundant/repeated data from the dataset.
The web has many aggregators, mirrors, templated pages or just otherwise repeated content spread over different domains and webpages. Sometimes, these duplicated pages can even be introduced by the crawler itself, when different links point to the same page.
Removing these duplicates (deduplicating) has been correlated with improvements in model performance
There are different ways to identify and even define
duplicated data. Common approaches rely on hashing techniques to speed up the process, or on building
efficient data structures to index the data (like suffix arrays). Methods can also be “fuzzy”, by using some
similarity metric to mark documents as duplicates, or “exact” by checking for exact matches between two
documents (or lines, paragraphs, or whatever other granularity level being used)
Following RefinedWeb
This would mean that for two documents with a similarity (s) of 0.7, 0.75, 0.8 and 0.85, the probability that they would be identified as duplicates would be 56%, 77%, 92% and 98.8% respectively (1-(1-s^8)^{14}). See the plot below for a match probability comparison between our setup with 112 hashes and the one from RefinedWeb, with 9000 hashes, divided into 450 buckets of 20 hashes (that requires a substantially larger amount of compute resources, as each individual hash must be computed, stored and then compared with hashes from other documents):
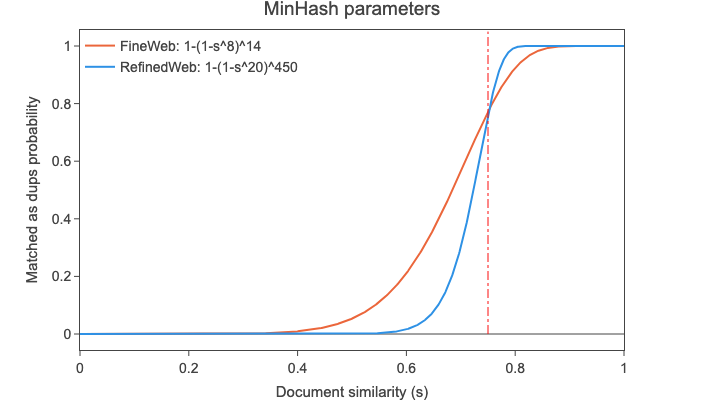
While the high number of hash functions in RefinedWeb allows for a steeper, more well defined cut off (documents with real similarity near the threshold are more likely to be correctly identified), we believe the compute and storage savings are a reasonable trade off.
It should also be noted that intra-document deduplication is already handled by our repetition filter, which removes documents with many repeated lines and paragraphs.
Initially, we were operating under the assumption that more deduplication is always better, so our first approach was to take the entire dataset (all 90+ dumps) and deduplicate them together as one big dataset using MinHash.
We did this in an iterative manner: starting with the most recent dump (which at the time was 2023-50) and proceeding chronologically until we reached the oldest crawl. We deduplicated each dump not only within itself, but removing any document matching any other documents in the previously processed dumps.
For instance, for the second most recent dump (2023-40 at the time), we deduplicated it against the most recent one in addition to within itself. As a result, the older the dumps, the larger the number of dumps it was deduplicated against and the more data we removed from it (indeed, in the oldest dumps, the deduplication step removed more than 90% of the base filtered data).
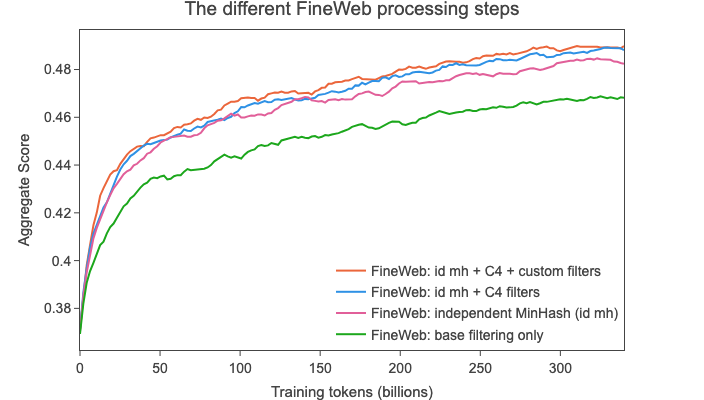
Deduplicating the dataset in this manner resulted in 4 trillion tokens of data, but, quite surprisingly to us, when training on a randomly sampled 350 billion tokens subset, our ablation models showed next to no improvement over a model trained on the non deduplicated data, scoring far below its predecessor RefinedWeb on our aggregate of tasks (see graph below).
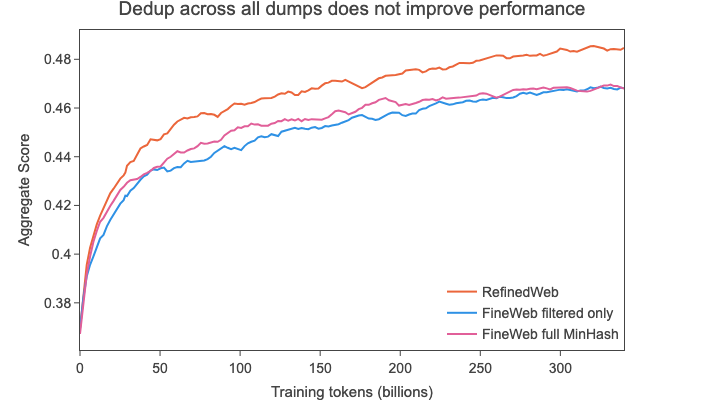
This challenged our assumption that more deduplication would inevitably result in higher benchmark scores, so we decided to take a closer look at one of the oldest dumps, dump 2013-48:
As an experiment, we tried training two models on 28 billion tokens sampled from the following data from 2013-48:
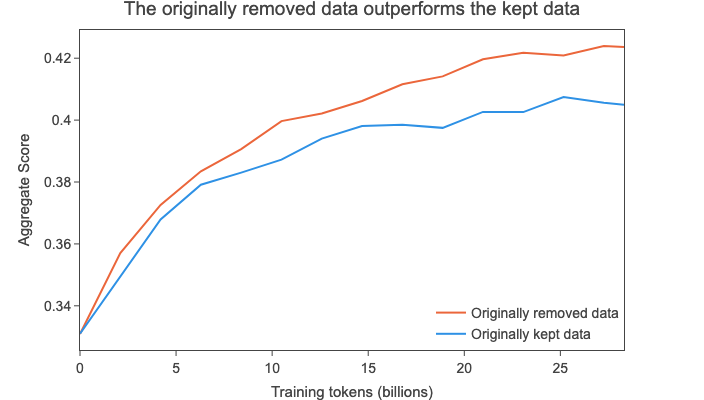
These results show that, for this older dump taken in isolation, the data that was kept (10% of the original data) was actually worse than the 90% of data we
removed
We decided to experiment with an alternative approach: we deduplicated each dump with MinHash individually (independently of the other dumps). This resulted in 20 trillion tokens of data.
When training on a random sample from this dataset we see that it now matches RefinedWeb’s performance (see curves below):
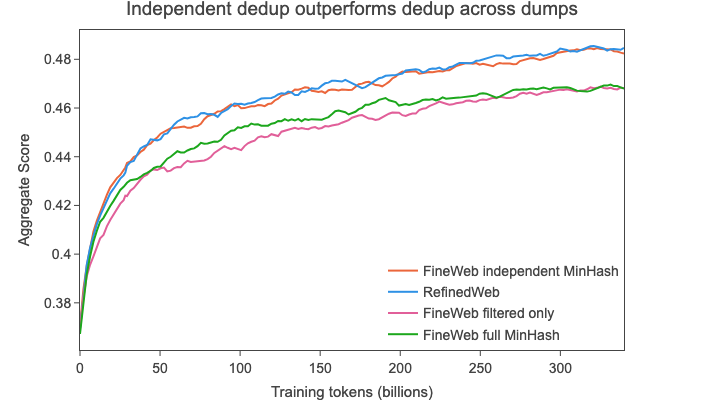
We hypothesize that the main improvement gained from deduplication is the removal of very large clusters that are present in every single dump (you will find some examples of these clusters in the RefinedWeb paper, each containing hundreds of thousands of documents) and that further deduplication for clusters with a low number of duplicates (less than ~100 i.e. the number of dumps) actually harms performance: data that does not find a duplicate match in any other dump might actually be worse quality/more out of distribution (as evidenced by the results on the 2013-48 data).
While you might see some performance improvement when deduplicating a few dumps together, at the scale of the entire dataset (all the dumps), the effect from this upsampling of lower quality data side effect seems to be more impactful.
One possibility to consider is that as filtering quality improves, this effect may not be as prevalent, since the filtering might be able to remove some of this lower quality data. We also experimented with applying different, and often “lighter”, deduplication approaches on top of the individually deduplicated dumps. You can read about them further below.
Given the nature of deduplication, its effect is not always very visible in a smaller slice of the dataset (such as 28B tokens, the size we used for our filtering ablations). Furthermore, one must consider the fact that there are specific effects at play when deduplicating across all CommonCrawl dumps, as some URLs/pages are recrawled from one dump to the next.
To visualize the effect of scaling the number of training tokens on measuring deduplication impact, we considered the following (very extreme and unrealistic regarding the degree of duplication observed) theoretical scenario:
We then simulated uniformly sampling documents from this entire dataset of 20 trillion tokens, to obtain subsets of 1B, 10B, 100B, 350B and 1T tokens. In the image below you can see how often each document would be repeated.
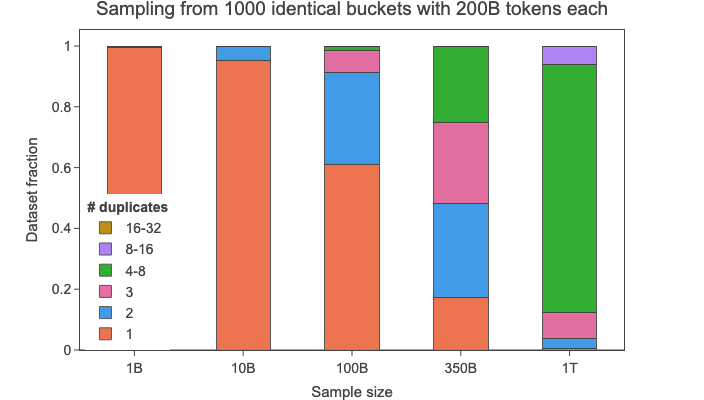
For 1B almost all documents would be unique (#duplicates=1), despite the fact that in the entire dataset each document is repeated 100 times (once per dump). We start seeing some changes at the 100B scale (0.5% of the total dataset), with a large number of documents being repeated twice, and a few even 4-8 times. At the larger scale of 1T (5% of the total dataset), the majority of the documents are repeated up to 8 times, with some being repeated up to 16 times.
We ran our performance evaluations for the deduplicated data at the 350B scale, which would, under this theoretical scenario, be made up of a significant portion of documents duplicated up to 8 times. This simulation illustrates the inherent difficulties associated with measuring deduplication impact on the training of LLMs, once the biggest duplicate clusters have been removed.
To build on top of our newly found method (independently deduplicating each dump). We attempted to improve the performance by further deduplicating the independently minhash deduped 20 trillion tokens of data with alternative global (over all dumps) deduplication methods. We explored the following approaches:
The performance of the models trained on each of these was consistently worse (even if to different degrees) than that of the original independently deduplicated data:
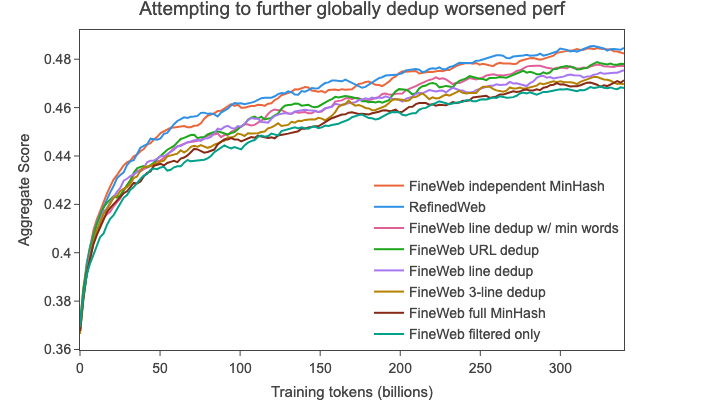
By this point we had reached the same performance of the previous work we attempted to reproduce and extend:
RefinedWeb, using our base filtering and independent MinHash. Still, on our aggregate of tasks, another heavily filtered dataset, the C4 dataset
We therefore set out to find new filtering steps that would, at first, allow us to match the performance of C4 and, at a second stage, surpass it. A natural starting point was to look into the processing of C4 itself.
The C4
dataset was first released in 2019. It was obtained from the 2019-18 CommonCrawl dump by
removing non english data, applying some heuristic filters on both the line and document level,
deduplicating on the line level, and removing documents containing words from a word blocklist.
Despite its age and limited size for current standards (around 175B gpt2 tokens), this dataset is, to this day, a common sub-set of typical LLM training, being used in models such as the relatively recent Llama1
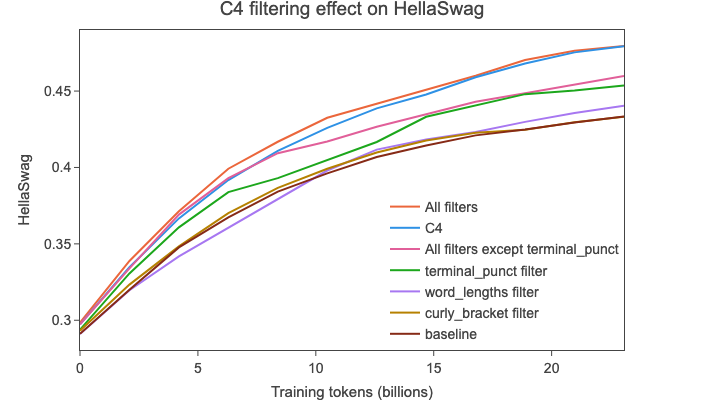
{) allows us to match C4’s HellaSwag performance ("All filters" vs "C4" curves, respectively).
We decided to apply all C4 filters mentioned above except the terminal punctuation one. We validated these results with a longer run, which you will find in a plot in the next section.
To develop new heuristic filters and select their thresholds we devised a systematic process:
Due to our (new) assumption that global MinHash greatly upsamples lower quality data in the oldest dumps, we computed metrics on both the independently MinHashed and the (worse quality) global MinHashed versions of the 2013-48 and 2015-22 crawls (two older crawls). We then compared the statistics at a macro level, by looking at the distribution of these metrics for each one.
Perhaps not too surprisingly given our findings for deduplication, we found significant
disparities in most of the metrics for the two deduplication methods. For instance, the line-char-duplicates
metric (nb. of characters in duplicated lines / nb. characters), roughly doubled from the independent dedup
(0.0053 for 2015-22 and 0.0058 for 2013-48), to the global dedup (0.011 for 2015-22 and 0.01 for 2013-48),
indicating that the latter had higher inter-document repetition.
Following the process listed above for these datasets yielded seventeen candidate metric-threshold pairs. In the image below, you can see three of these histograms:
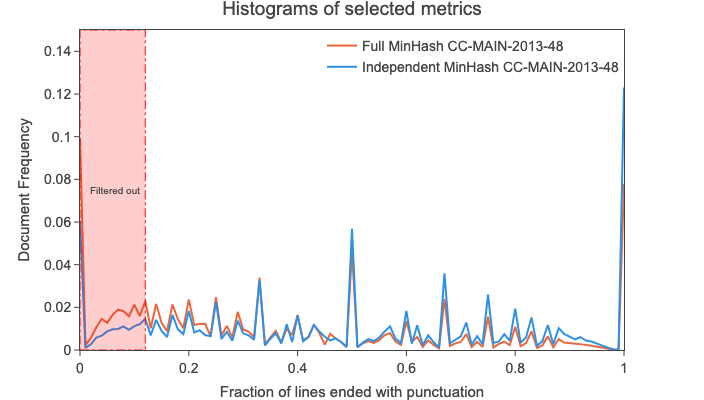
As an example, we inspected the histograms of "fraction of lines ending with punctuation" (see the image above) and observed an increased document density of global MinHash at around 0.12. We then filtered with this threshold and found that the removed data had a higher amount of short lists or consisted of only document layout text ("Home", "Sign up", etc).
We then assessed the effectiveness of these seventeen newly created filters, by conducting several of our 28 billion tokens ablation runs on the 2019-18 crawl. Out of all those runs, we identified three filters (the ones based on the histograms above) that demonstrated the most significant improvements on the aggregate score:
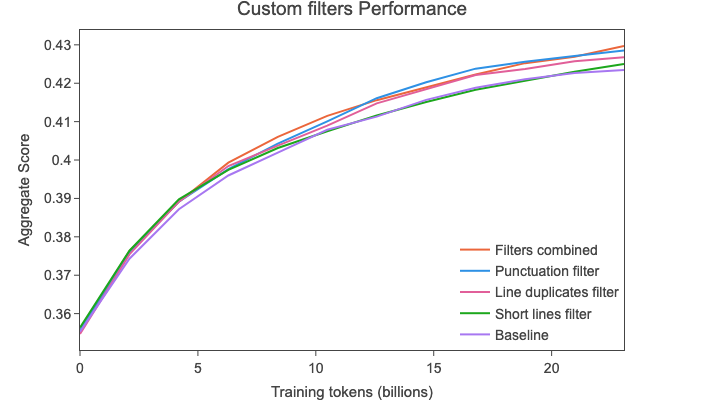
These filters allowed us to further improve performance and to, notably, surpass the C4 dataset performance while providing a much larger dataset at the same time.
The final 🍷 FineWeb dataset comprises 15T tokens and includes the following previously mentioned steps, in order, each providing a performance boost on our group of benchmark tasks:
We compared 🍷 FineWeb with the following datasets that are usually considered the highest quality openly accessible web-scale datasets (we also indicate for each the approximate number of tokens in the public version of the dataset):
You will find the 350B-tokens-trained ablation models openly accessible and gathered in this collection. We have uploaded checkpoints at every 1000 training steps. You will also find our full evaluation results here.
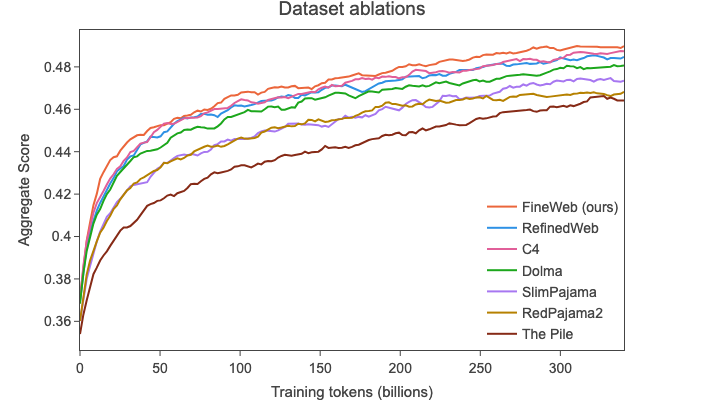
🍷 FineWeb is thus – to the best of our knowledge – the open dataset leading to the current highest model performances while allowing to train on several trillion tokens.
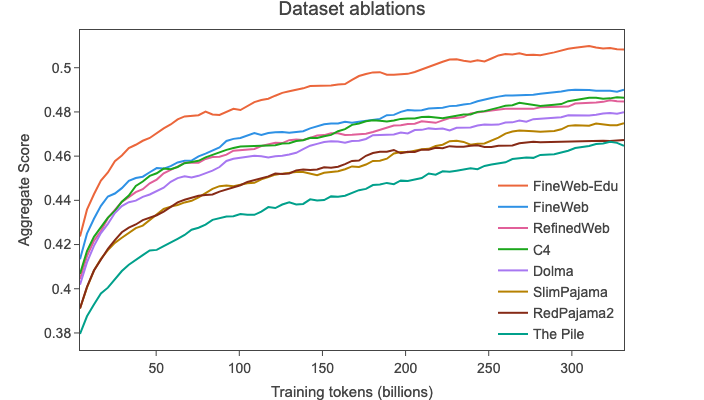
📚 FineWeb-Edu is an additional development of FineWeb that we are excited to introduce in this tech report and openly release. 📚 FineWeb-Edu is based on a new approach that has recently emerged for filtering LLM training datasets: using synthetic data to develop classifiers for identifying educational content. This technique was notably used in the trainings of Llama 3
The popular Phi3 models were trained on 3.3 and 4.8 trillion tokens, with the paper
Our training data consists of heavily filtered publicly available web data (according to the 'educational level') from various open internet sources, as well as synthetic LLM-generated data.
Similarly, Llama 3 blog post
We found that previous generations of Llama are good at identifying high-quality data, so we used Llama 2 to help build the text-quality classifiers that are powering Llama 3.
However, these classifiers and filtered datasets are not publicly available. To further enhance 🍷 FineWeb's quality, we developed an educational quality classifier using annotations generated by Llama-3-70B-Instruct to create 📚 FineWeb-Edu.
We used Llama-3-70B-Instruct to annotate 500k samples from 🍷 FineWeb, scoring each for their educational quality on a scale from 0 to 5.
We explored various prompt formats to automatically extract an educational score using an LLM and found that the additive scale by Yuan et al.

In terms of open-weight models to use for annotating the data, we experimented with several models including Mixtral-8x7B-Instruct and Mixtral-8x22B-Instruct, Llama-3-70B-Instruct as well as a jury gathering the scores from these three models
To scale our annotations to the trillions of tokens in FineWeb, we used the Llama3-70B annotations to train a small classifier. The model we used was a Snowflake-arctic-embed embedding model with a classification head with a single regression output on top of it. We trained this model on the 450,000 Llama 3 annotations for 20 epochs with a learning rate of 3e-4, freezing the embedding and encoder layers. We saved the checkpoint with the highest F1 score on our held-out validation set of 45k samples, treating Llama 3 annotations as ground-truth. After training, we rounded the scores to integers from 0 to 5.
We then converted the problem to a binary classification task by using a fixed threshold to determine if a file is educational. With a threshold of 3, the model achieved an F1 score of 82% on the validation set, indicating strong performance in distinguishing high-quality educational content.
The classifier is available at: HuggingFaceFW/fineweb-edu-classifier. The training and inference code is available on GitHub.
We applied the classifier to the 15T tokens of 🍷 FineWeb, a process that required 6,000 H100 GPU hours. We investigated the impact of using different thresholds for the filtering and found that using a threshold of 3 gave the best overall results. Although using a threshold higher than 3 improves performance on knowledge and reasoning intensive benchmarks, it significantly degrades performance on HellaSwag and PIQA. The plot below shows the performance of each threshold compared to FineWeb on six different benchmarks; it uses a 1.82B model trained on 8B tokens.
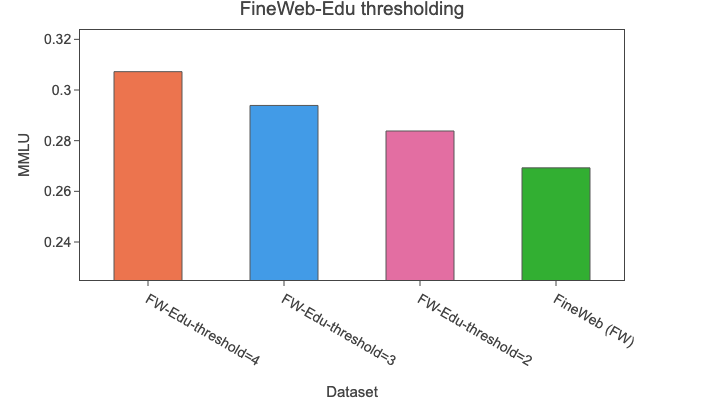
Note: this ablation was conducted on 8B tokens from the 2024-10 dump for both the FineWeb and FineWeb-Edu subsets, which might not be representative of the entire dataset. The next ablation shows that the findings for threshold 3 hold on a longer run of 350B tokens from all FineWeb dumps, except for HellaSwag, where we noticed a slight performance degradation.
We built 📚 FineWeb-Edu by filtering out samples with scores lower than 3. This removed 92% of the dataset, leaving us with 1.3 trillion educational tokens. To evaluate the effectiveness of this filtering at a larger scale, we conducted an ablation using a 1.82B model trained on 350 billion tokens, similar to the FineWeb filtering ablation mentioned above:
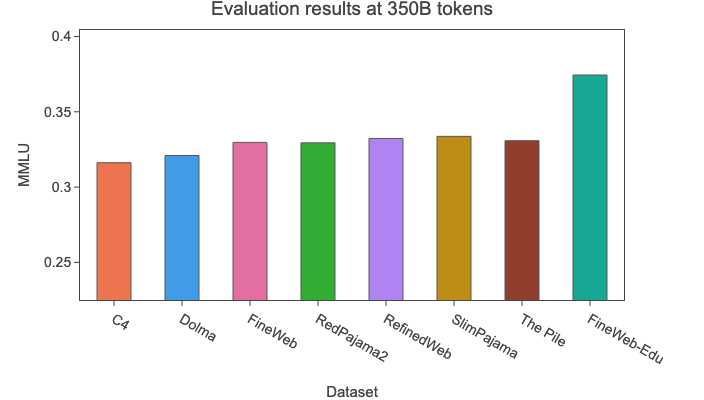
Here are the key highlights of the ablation results above:
Given that a threshold of 2 also demonstrated strong performance while retaining more data, we are releasing an additional dataset filtered with this threshold, containing 5.4 trillion tokens under HuggingFaceFW/fineweb-edu-score-2.
You can find the two datasets along with the classifier used for the filtering in this collection.
Just like fine wine, not all crawls are created equal.
While ablating filtering steps, we noticed that certain crawls outperformed others by a significant margin. We decided to investigate this phenomenon.
For each crawl, we trained two 1.8B models on 27 billion tokens randomly sampled from that crawl's data (after the base filtering and MinHash deduplication steps), where each run had a different random 27BT sampling of this data. We trained 192 such models, totaling over 60 thousand H100 GPU-hours. We subsequently took the last 3 checkpoints for both runs and plotted the average of these 6 data points per crawl.
The plot below clearly shows that some dumps perform far worse than others. Each year has a different color, and the number of crawls per year also varies.
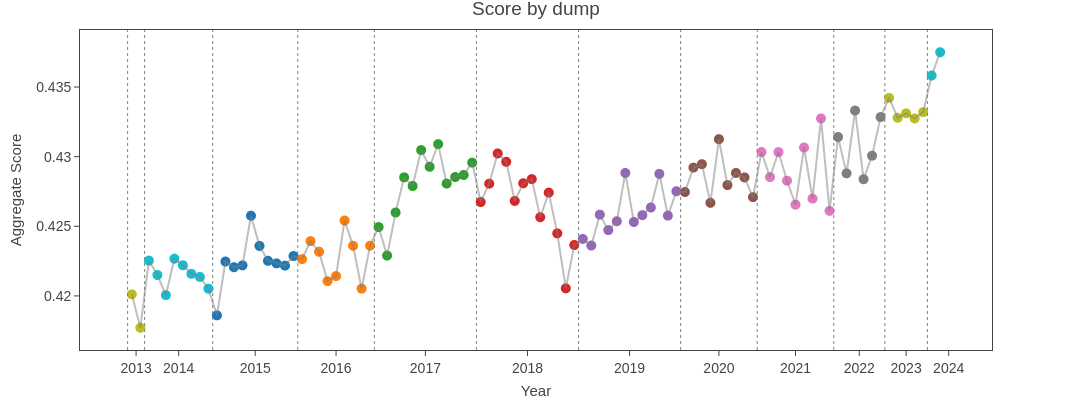
We investigated possible causes for this behaviour such as changes in the most common URLs of each dump, as well as potential benchmark contamination, but could not find any conclusive explanation. We leave further investigation for future work.
We wondered if the strong performance of the last few crawls could be, in part, attributed to the presence of a larger quantity of synthetic data (data generated by LLMs). Such a change would not be surprising due to the recent increase in popularity of LLMs, notably of ChatGPT.
Since, to the best of our knowledge, there is no foolproof method to detect synthetic data, we opted to use a proxy metric: we measured the frequency of the
following words in each crawl: "delve", "as a large language model", "it's important to note", "rich tapestry",
"intertwined", "certainly!", "dive into", all of which are commonly used by ChatGPT.
It is important to note that not all samples containing one of these phrases were necessarily generated by ChatGPT (and also that many ChatGPT generated samples do not contain any of these phrases), but assuming that the amount of synthetic data were to not change across crawls, one would expect these frequencies to remain approximately constant over time.
The results are shown in the following plot:
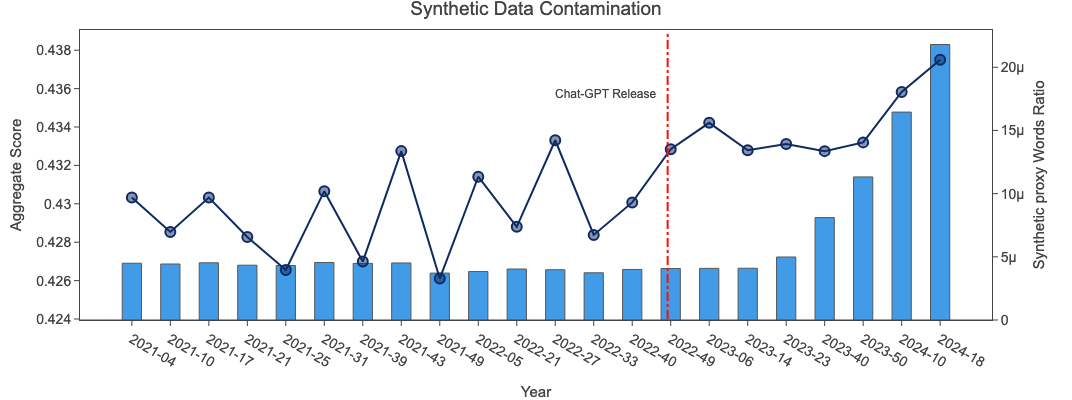
While the frequency remained approximately constant until 2023-14 (ChatGPT was released at the end of 2022), we find a steep increase of our proxy metric in recent crawls. While this simple test is not enough to conclude that ChatGPT completions and other synthetic data is improving the quality of the most recent crawl, it at the very least does not seem to drastically harm it.
We expect to continue seeing increasing quantities of synthetic data on new CC crawls. However, while for relatively small trainings this data does not seem to harm performance (and might actually improve it), it is not clear that this holds for much larger trainings.
Through our open science efforts we hope to keep shining a light on the black box that is the training of high performance large language models as well as to give every model trainer the ability to create state-of-the-art LLMs. We are excited to continue iterating on FineWeb and to release increasingly better filtered subsets of web data, in a fully open and reproducible manner.
In the short term, we are looking forward to applying the learnings from (English) FineWeb to other languages. While English currently dominates the LLM landscape, we believe that making high quality web data in other languages as accessible as possible would be incredibly impactful.
In a nutshell: the future is bright and exciting for studying the science of creating datasets at scale and in the open 🤗.
For attribution in academic contexts, please cite this work as
Penedo, et al., "The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale", 2024.
BibTeX citation
@inproceedings{
penedo2024the,
title={The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale},
author={Guilherme Penedo and Hynek Kydl{\'\i}{\v{c}}ek and Loubna Ben allal and Anton Lozhkov and Margaret Mitchell and Colin Raffel and Leandro Von Werra and Thomas Wolf},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024},
url={https://openreview.net/forum?id=n6SCkn2QaG}
}